NUMA 概念
NUMA的几个概念(Node,socket,core,thread)
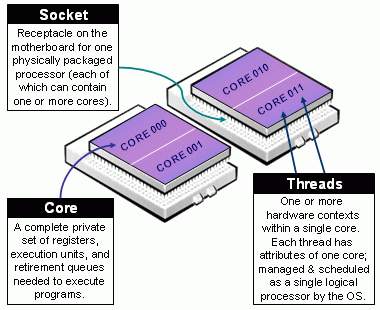
- socket就是主板上的CPU插槽;
- core就是socket里独立的一组程序执行的硬件单元,比如寄存器,计算单元等;
- thread:就是超线程hyperthread的概念,逻辑的执行单元,独立的执行上下文,但是共享core内的寄存器和计算单元。
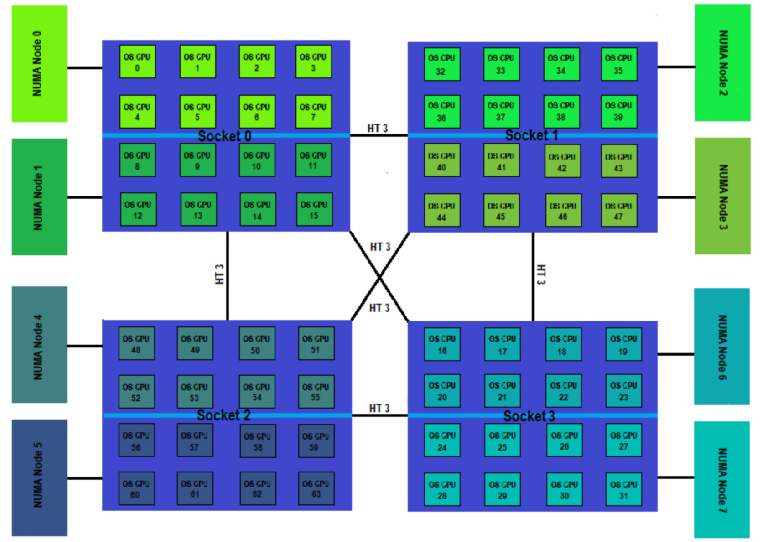
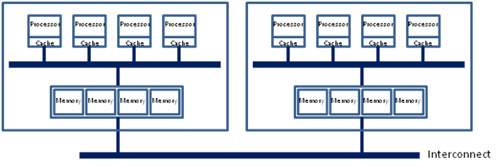
NUMA体系结构中多了Node的概念,这个概念其实是用来解决core的分组的问题,具体参见下图来理解(图中的OS CPU可以理解thread,那么core就没有在图中画出),从图中可以看出每个Socket里有两个node,共有4个socket,每个socket 2个node,每个node中有8个thread,总共4(Socket)× 2(Node)× 8 (4core × 2 Thread) = 64个thread。
另外每个node有自己的内部CPU,总线和内存,同时还可以访问其他node内的内存,NUMA的最大的优势就是可以方便的增加CPU的数量,因为Node内有自己内部总线,所以增加CPU数量可以通过增加Node的数目来实现,如果单纯的增加CPU的数量,会对总线造成很大的压力,所以UMA结构不可能支持很多的核。
《NUMA Best Practices for Dell PowerEdge 12th Generation Servers》
根据上面提到的,由于每个node内部有自己的CPU总线和内存,所以如果一个虚拟机的vCPU跨不同的Node的话,就会导致一个node中的CPU去访问另外一个node中的内存的情况,这就导致内存访问延迟的增加。在有些特殊场景下,比如NFV(Network Function Virtualization)环境中,对性能有比较高的要求,就非常需要同一个虚拟机的vCPU尽量被分配到同一个Node中的pCPU上,所以在OpenStack的Kilo版本中增加了基于NUMA感知的虚拟机调度的特性。
查看机器的NUMA拓扑结构
1 | [root@local ~]$ lscpu |
可以看出当前机器有2个sockets,每个sockets包含1个numa node,每个numa node中有12个cores,每个cores包含2个thread,所以总的threads数量=2x1x12x2=48.
NUMA 历史
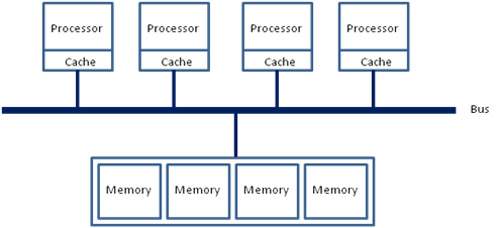
在若干年前,对于x86架构的计算机,那时的内存控制器还没有整合进CPU,所有内存的访问都需要通过北桥芯片来完成。此时的内存访问如下图所示,被称为UMA(uniform memory access, 一致性内存访问)。 这样的访问对于软件层面来说非常容易实现:总线模型保证了所有的内存访问是一致的,不必考虑由不同内存地址之前的差异。
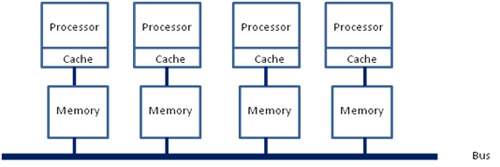
之后的x86平台经历了一场从“拼频率”到“拼核心数”的转变,越来越多的核心被尽可能地塞进了同一块芯片上,各个核心对于内存带宽的争抢访问成为了瓶颈;此时软件、OS方面对于SMP多核心CPU的支持也愈发成熟;再加上各种商业上的考量,x86平台也搞了NUMA(Non-uniform memory access, 非一致性内存访问)。
NUMA中,虽然内存直接attach在CPU上,但是由于内存被平均分配在了各个die(核心)上。只有当CPU访问自身直接attach内存对应的物理地址时,才会有较短的响应时间(后称Local Access)。而如果需要访问其他CPU attach的内存的数据时,就需要通过inter-connect通道访问,响应时间就相比之前变慢了(后称Remote Access)。所以NUMA(Non-Uniform Memory Access)就此得名
在这种架构之下,每个Socket都会有一个独立的内存控制器IMC(integrated memory controllers, 集成内存控制器),分属于不同的socket之内的IMC之间通过QPI link通讯。
然后就是进一步的架构演进,由于每个socket上都会有多个core进行内存访问,这就会在每个core的内部出现一个类似最早SMP架构相似的内存访问总线,这个总线被称为IMC bus。
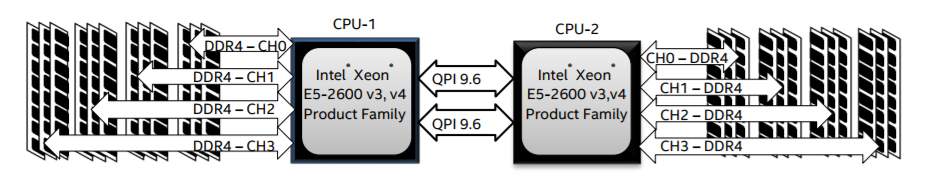
于是,很明显的,在这种架构之下,两个socket各自管理1/2的内存插槽,如果要访问不属于本socket的内存则必须通过QPI link。也就是说内存的访问出现了本地/远程(local/remote)的概念,内存的延时是会有显著的区别的。
以Xeon 2699 v4系列CPU的标准来看,两个Socket之之间通过各自的一条9.6GT/s的QPI link互访。而每个Socket事实上有2个内存控制器。双通道的缘故,每个控制器又有两个内存通道(channel),每个通道最多支持3根内存条(DIMM)。理论上最大单socket支持76.8GB/s的内存带宽,而两个QPI link,每个QPI link有9.6GT/s的速率(~57.6GB/s)事实上QPI link已经出现瓶颈了。
核心数还是源源不断的增加,Skylake桌面版本的i7 EE已经有了18个core,Skylake Xeon 28个Core(2017)。为了塞进更多的core,原本核心之间类似环网的设计变成了复杂的路由。 由于这种架构上的变化,导致内存的访问变得更加复杂。两个IMC也有了local/remote的区别,在保证兼容性的前提和性能导向的纠结中,系统允许用户进行更为灵活的内存访问架构划分。于是就有了“NUMA之上的NUMA”这种妖异的设定(SNC)。
性能提升
内存访问
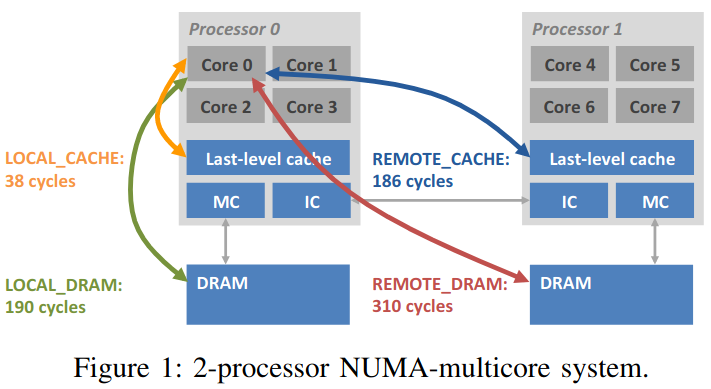
在一个NUMA node上的进程访问本NUMA node的内存 比 访问其他NUMA node的内存快很多。
引用《nderstanding the NUMA Memory System Performance of Multithreaded Workloads》
进程调度
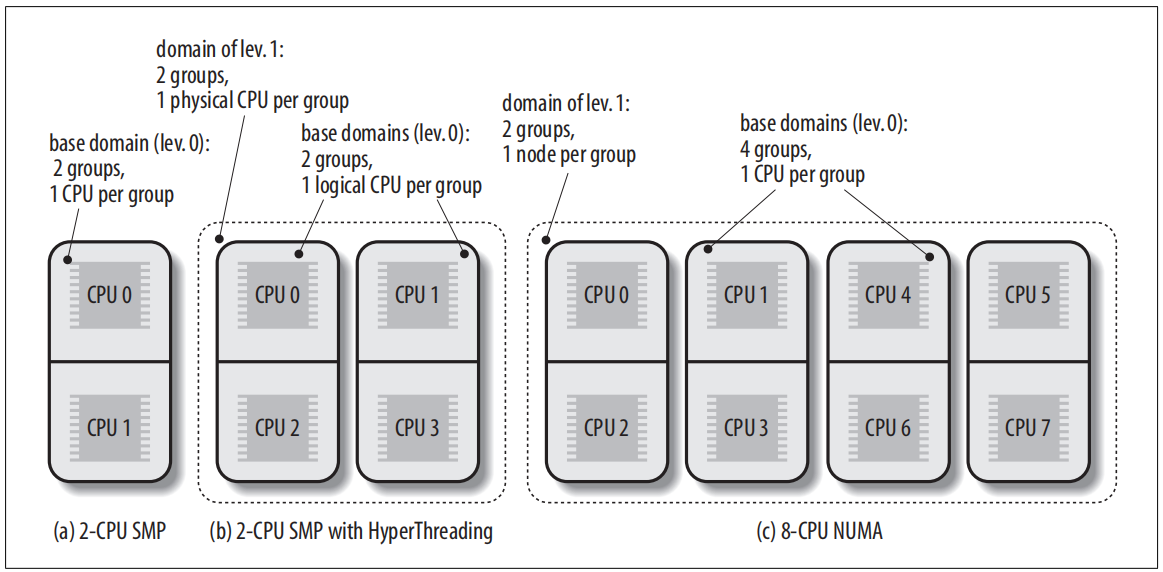
Linux内核调度以sheduling domain为层级进行调度,调度器尽量平衡一个domain下的节点的负载。
引用《Understanding linux kernel》
a scheduling domain is a set of CPUs whose workloads should be kept balanced by the kernel.
- 在一个启用了NUMA支持的Linux中,Kernel尽量不会将任务内存从一个NUMA node搬迁到另一个NUMA node。 为了尽可能的优化性能,在正常的调度之中,CPU的core也会尽可能的使用可以local访问的本地core。
- 一旦当某个NUMA node的负载超出了另一个node一个阈值(默认25%),则认为需要在此node上减少负载,不同的NUMA结构和不同的负载状况,系统会对进程进行迁移。在这种情况下将会产生内存的remote访问。
- NUMA node之间有不同的拓扑结构,各个 node 之间的访问会有一个距离(node distances)的概念,
如numactl -H命令的结果有这样的描述:
1 | [root@local ~]$ numactl -H |
可以看出:0 node 到0 node之间距离为10,是最近的距离。
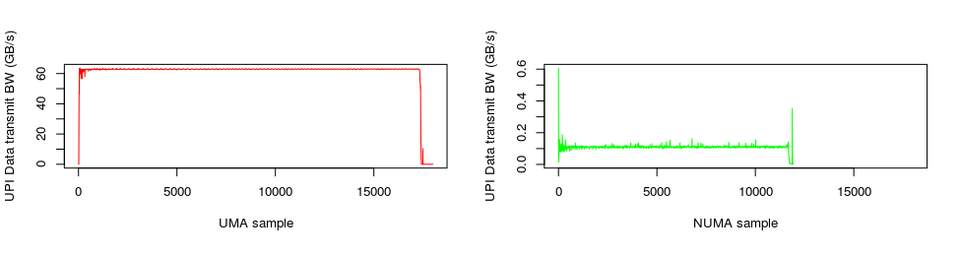
上图记录了某个Benchmark工具,在开启/关闭NUMA功能时QPI带宽消耗的情况。很明显的是,在开启了NUMA支持以后,QPI的带宽消耗有了两个数量级以上的下降,性能也有了显著的提升!
通常情况下,用户可以通过numactl来进行NUMA访问策略的手工配置,cgroup中cpuset.mems也可以达到指定NUMA node的作用。
Numa内存分配策略有四种:
- 缺省default:总是在本地节点分配(当前进程运行的节点上)。
- 绑定bind:强制分配到指定节点上。
- 交叉interleavel:在所有节点或者指定节点上交叉分配内存。
- 优先preferred:在指定节点上分配,失败则在其他节点上分配
以numactl命令为例,它有如下策略:
- –interleave=nodes //允许进程在多个node之间交替访问
- –membind=nodes //将内存固定在某个node上,CPU则选择对应的core。
- –cpunodebind=nodes //与membind相反,将CPU固定在某(几)个core上,内存则限制在对应的NUMA node之上。
- –physcpubind=cpus //与cpunodebind类似,不同的是物理core。
- –localalloc //本地配置
- –preferred=node //按照推荐配置
对于某些大内存访问的应用,比如Mongodb,将NUMA的访问策略制定为interleave=all则意味着整个进程的内存是均匀分布在所有的node之上,进程可以以最快的方式访问本地内存。 北桥有一个功能就是PCI/PCIe控制器,南桥(PCH)整合了PCIe控制器。
在PCIe channel上也是有NUMA亲和性的。
比如:查看网卡em1的NUMA
1 | [root@local ~]$ numactl --prefer netdev:em1 --show |
PCI address 为00:1f.2的SATA控制器,用到了pci:
00:1f.2 SATA controller: Intel Corporation C610/X99 series chipset 6-Port SATA Controller [AHCI mode] (rev 05)
1 | [root@local ~]$ numactl --prefer pci:00:1f.2 --show |
查看当前系统numa策略:
1 | [root@local ~]$ numactl --show |
查看当前numa的节点情况:
1 | [root@local ~]$ numactl --hardware |
NUMA带来的问题
- MySQL – The MySQL “swap insanity” problem and the effects of the NUMA architecture
- PostgreSQL – PostgreSQL, NUMA and zone reclaim mode on linux
- Oracle – Non-Uniform Memory Access (NUMA) architecture with Oracle database by examples
- Java – Optimizing Linux Memory Management for Low-latency / High-throughput Databases
这些问题都是:“因为CPU亲和策略导致的内存分配不平均”及“NUMA Zone Claim内存回收”有关,而和数据库种类并没有直接联系。
数据库与NUMA
MySQL在NUMA架构上遇到的典型问题
- The MySQL “swap insanity” problem and the effects of the NUMA architecture
- A brief update on NUMA and MySQL
大致分析如下:
- CPU规模因摩尔定律指数级发展,而总线发展缓慢,导致多核CPU通过一条总线共享内存成为瓶颈
- 于是NUMA出现了,CPU平均划分为若干个Chip(不多于4个),每个Chip有自己的内存控制器及内存插槽
- CPU访问自己Chip上所插的内存时速度快,而访问其他CPU所关联的内存(下文称Remote Access)的速度相较慢三倍左右
- 于是Linux内核默认使用CPU亲和的内存分配策略,使内存页尽可能的和调用线程处在同一个Core/Chip中
- 由于内存页没有动态调整策略,使得大部分内存页都集中在CPU 0上
- 又因为Reclaim默认策略优先淘汰/Swap本Chip上的内存,使得大量有用内存被换出
- 当被换出页被访问时问题就以数据库响应时间飙高甚至阻塞的形式出现了
解决方案:
- numactl --interleave=all
- 在MySQL进程启动前,使用sysctl -q -w - vm.drop_caches=3清空文件缓存所占用的空间
- Innodb在启动时,就完成整个Innodb_buffer_pool_size的内存分配
不过这种三合一的解决方案只是减少了NUMA内存分配不均,导致的MySQL SWAP问题出现的可能性。如果当系统上其他进程,或者MySQL本身需要大量内存时,Innodb Buffer Pool的那些Page同样还是会被Swap到存储上。于是又在这基础上出现了另外几个进阶方案
- 配置vm.zone_reclaim_mode = 0使得内存不足时去remote memory分配优先于swap out local page
- echo -15 > /proc//oom_adj调低MySQL进程被OOM_killer强制Kill的可能
- memlock
- 对MySQL使用Huge Page(黑魔法,巧用了Huge Page不会被swap的特性)
为什么Interleave的策略就解决了问题?
借用两张 Carrefour性能测试 的结果图,可以看到几乎所有情况下Interleave模式下的程序性能都要比默认的亲和模式要高,有时甚至能高达30%。究其根本原因是Linux服务器的大多数workload分布都是随机的:即每个线程在处理各个外部请求对应的逻辑时,所需要访问的内存是在物理上随机分布的。而Interleave模式就恰恰是针对这种特性将内存page随机打散到各个CPU Core上,使得每个CPU的负载和Remote Access的出现频率都均匀分布。相较NUMA默认的内存分配模式,死板的把内存都优先分配在线程所在Core上的做法,显然普遍适用性要强很多。
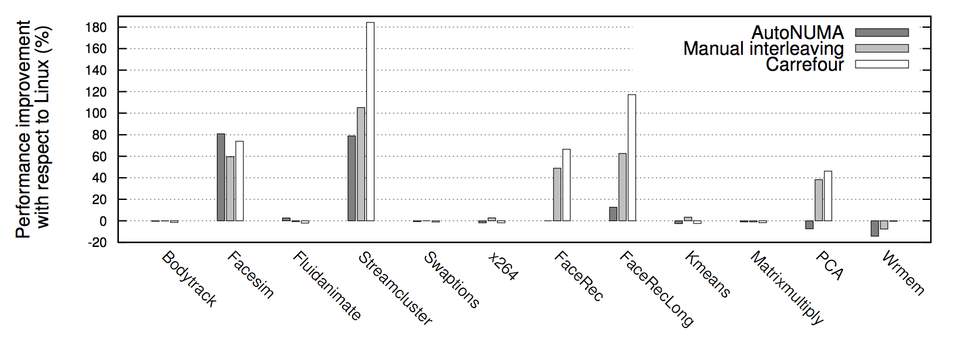
也就是说,像MySQL这种外部请求随机性强,各个线程访问内存在地址上平均分布的这种应用,Interleave的内存分配模式相较默认模式可以带来一定程度的性能提升。此外各种论文 中也都通过实验证实,真正造成程序在NUMA系统上性能瓶颈的并不是Remote Acess带来的响应时间损耗,而是内存的不合理分布导致Remote Access将interconnect这个小水管塞满所造成的结果。而Interleave恰好,把这种不合理分布情况下的Remote Access请求平均分布在了各个小水管中。所以这也是Interleave效果奇佳的一个原因。
那是不是简简单单的配置个Interleave就已经把NUMA的特性和性能发挥到了极致呢?
答案是否定的,目前Linux的内存分配机制在NUMA架构的CPU上还有一定的改进空间。
例如:Dynamic Memory Loaction, Page Replication。
Dynamic Memory Relocation
MySQL的线程分为两种,用户线程(SQL执行线程)和内部线程(内部功能,如:flush,io,master等)。对于用户线程来说随机性相当的强,但对于内部线程来说他们的行为以及所要访问的内存区域其实是相对固定且可以预测的。如果能对于这把这部分内存集中到这些内存线程所在的core上的时候,就能减少大量Remote Access,潜在的提升例如Page Flush,Purge等功能的吞吐量,甚至可以提高MySQL Crash后Recovery的速度(由于recovery是单线程)。
那是否能在Interleave模式下,把那些明显应该聚集在一个CPU上的内存集中在一起呢?很可惜,Dynamic Memory Relocation这种技术目前只停留在理论和实验阶段。我们来看下难点:要做到按照线程的行为动态的调整page在memory的分布,就势必需要做线程和内存的实时监控(profile)。对于Memory Access这种非常异常频繁的底层操作来说增加profile入口的性能损耗是极大的。
Page Replication
一些动态加载的库,把他们放在任何一个线程所在的CPU都会导致其他CPU上线程的执行效率下降。而这些共享数据往往读写比非常高,如果能把这些数据的副本在每个Memory Zone内都放置一份,理论上会带来较大的性能提升,同时也减少在interconnect上出现的瓶颈。由于缺乏硬件级别(如MESI协议的硬件支持)和操作系统原生级别的支持,Page Replication在数据一致性上维护的成本显得比他带来的提升更多。因此这种尝试也仅仅停留在理论阶段。当然,如果能得到底层的大力支持,相信这个方案还是有极大的实际价值的。
关闭NUMA特性的方法
- 硬件层,在BIOS中设置关闭
- OS内核,启动时设置numa=off
- 进程,numactl 进程启动时。numactl --interleave=all
NUMA取舍
指定numa
在运行程序的时候使用numactl -m和-physcpubind就能制定将这个程序运行在哪个cpu和哪个memory中:
numactl –physcpubind=2,6 ./program
玩转cpu-topology(站点已经无法访问) 的测试中显示当程序只使用一个node资源和使用多个node资源的比较表(差不多是38s与28s的差距)。所以限定程序在numa node中运行是有实际意义的。
指定numa带来的问题
SWAP的罪与罚 文章就说到了一个numa的陷阱的问题。现象是当你的服务器还有内存的时候,发现它已经在开始使用swap了,甚至已经导致机器出现停滞的现象。如果一个进程限制它只能使用自己的numa节点的内存,那么当自身numa node内存使用光之后,就不会去使用其他numa node的内存了,会开始使用swap,甚至更糟的情况,机器没有设置swap的时候,可能会直接死机!
所以你可以使用numactl --interleave=all来取消numa node的限制。
根据具体业务决定NUMA的使用:
- 如果你的程序是会占用大规模内存的,你大多应该选择关闭numa node的限制。因为这个时候你的程序很有几率会碰到numa陷阱。
- 如果你的程序并不占用大内存,而是要求更快的程序运行时间。你大多应该选择限制只访问本numa node的方法来进行处理。
