对要枚举出查询树上所有路径,从中找出一个代价最小的路径,是个NP问题,计算成本是非常高昂的。而当查询树的关系(表、子查询等)较少时,可以使用动态规划算法枚举出所有的路径找出最优解,但是当关系较多时,枚举的计算成本是我们无法接收的,这时就需要使用一些折中方案,如贪心算法、遗传算法。遗传算法借鉴自然界“优胜劣汰”的法则对路径进化,从而能找出相对较优的查询路径......
前言
数据库将SQL解析成一棵语法树后,就需要将语法树转换成查询树,然而查询树的每一个节点或者节点之间的连接都会有一种或者多种实现算法,而需要从中挑选出最优的节点组合。
路径表示单个表的访问方式(顺序访问、索引访问、点查)、两个表的连接方式(嵌套连接、归并连接、hash连接)以及多个表的连接顺序。 那么优化器需要枚举出所有的路径,从中挑选代价最低的路径来执行。
查询树上有的节点是可以直接进行优化的,如过滤、投影等,在查询树底部先将不需要的数据过滤掉,以减少数据量往查询树上层的传递以及操作的成本,这种优化是显而易见的,是基于经验的,我们称为启发式规则优化。 然而,有的优化是无法直接进行的,例如,A JOIN B,JOIN顺序A JOIN B 或者 B JOIN A都会输出正确的查询树结果,哪种顺序成本最低呢,这就需要基于统计数据来进行估算,找出代价最小的顺序,这种优化我们称之为基于成本的优化。
路径选择理论
因为不同的关系访问方式,ORDER、JOIN方式组合和排列非常多,而JOIN的优化是最为复杂的,所以我们就只讨论数据库是如何挑选出最优的JOIN路径的。
JOIN顺序的枚举
对于OUTER JOIN来说,JOIN顺序是固定的,所以路径数量相对较少(只需要考虑不同JOIN算法组成的路径);然而对于INNER JOIN来说,表之间的JOIN顺序是可以不同的,这样就可以由不同的JOIN组合、不同的JOIN顺序组成非常多的不同路径。 如A JOIN B JOIN C,路径有:
- (A⋈B)⋈C :就有两种排列顺序
(A JOIN B) JOIN C和C JOIN (A JOIN B) (A JOIN C) JOIN BA JOIN (C JOIN B)- 等等
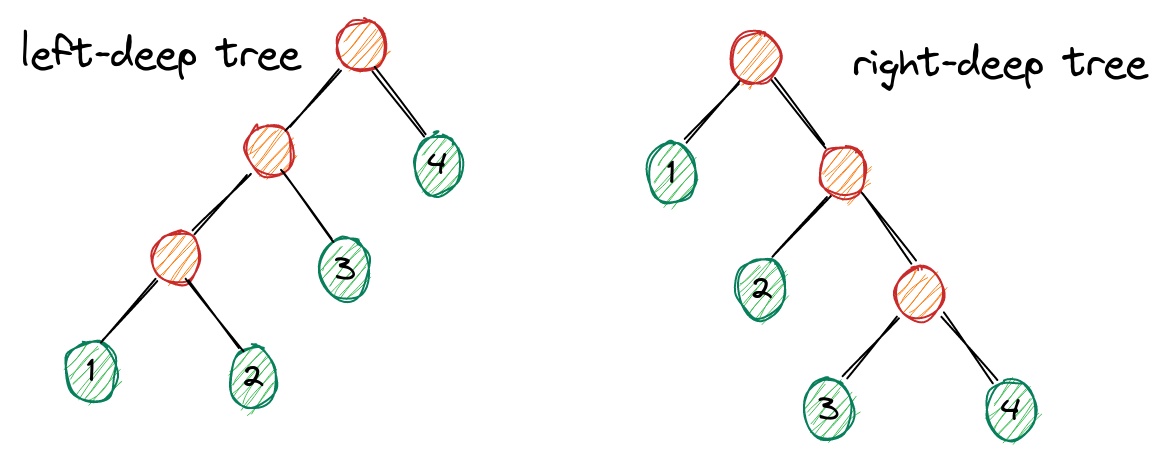
我们将所有join顺序组成的树的形态分为
- 左深树left-deep tree:((1⋈2)⋈3)⋈4
- 右深树right-deep tree:1⋈(2⋈(3⋈4))
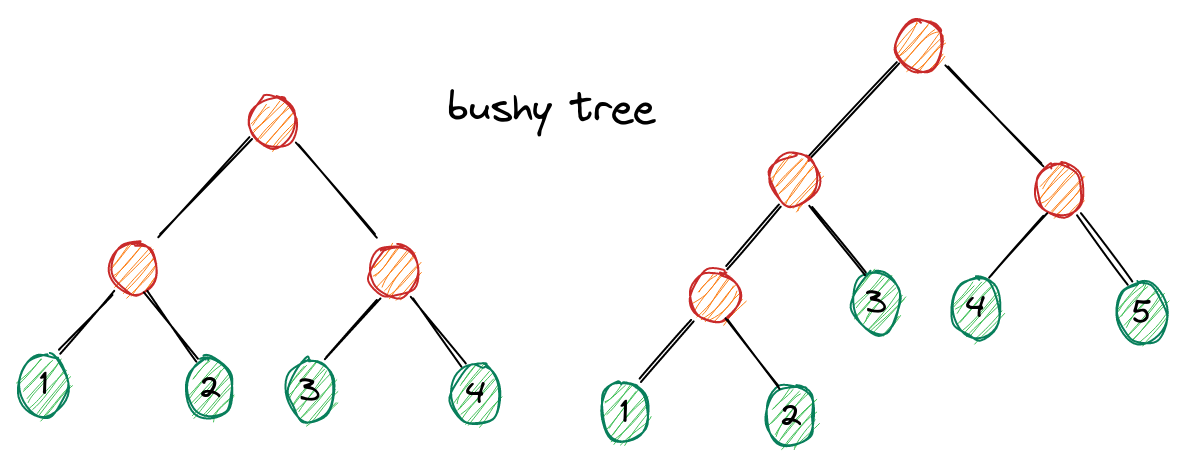
- 紧密树bushy tree: (1⋈2)⋈(3⋈4), ((1⋈2)⋈3)⋈(4⋈5)
JOIN连接的形状 就是一棵full binary tree 的形状,树形态的数量 是一个卡塔兰数(catalan number), 所以就有 \[ C_{n} = \frac{(2(n-1))!}{n!(n-1)!} \]
种形态的树。
而每种形态的树,都会有n!种排列, 所以n种关系(表,子查询等)就会有 (2(n − 1))!∕(n − 1)!种不同的JOIN路径。
例如4个表JOIN,组成的树的形态就有5种,而每种形态 4! 种排列,所以就有5 * 4! =120 种不同的JOIN路径。
如果是7个表连接,就有665280种JOIN路径!那么要将全部的JOIN路径枚举出来,是非常耗时的。
JOIN方式的枚举
JOIN一般有几种实现方式:嵌套连接、归并连接、hash连接等,所以不同的JOIN顺序还有这几种JOIN方式。
如:A⋈B就有两种排列顺序A JOIN B 和 B JOIN A
而根据不同的JOIN方式有:
A nested-loop join BA merge join BA hash join B
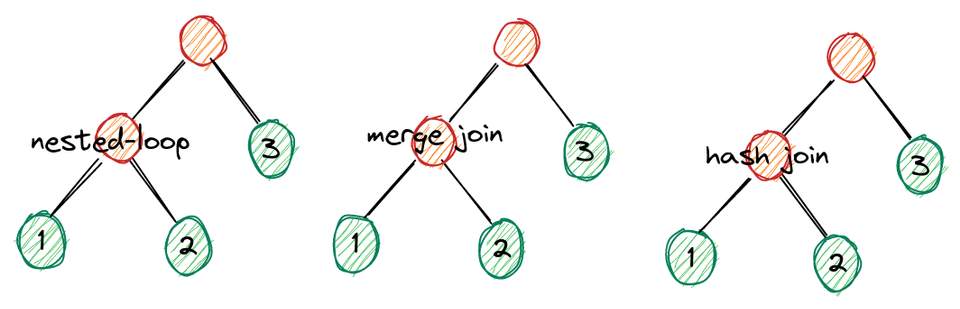
实现方式
通常数据库使用以下几种方法来从JOIN路径中找出成本最优的路径
- 动态规划:考虑全部子集,从中找出最优子集
- 贪心算法:考虑部分子集
- 随机算法:考虑部分子集,常见的有模拟退火算法,随机爬山算法,遗传算法等等
动态规划
遍历出所有的路径,记忆路径子集,避免重复计算,通过最优子问题构建出整个问题最优解。
这种方法能够计算出最优路径,但是如果表的个数变多,则“基于代价的动态规划算法”暴露出连接膨胀的问题。依据前面的计算,7个表就有665280种连接顺序,就算有大量子问题能避免重复计算,但整个计算成本还是相当巨大的。
如果表太多,我们就要取舍,追求次最优或者局部最优解(尽量扩大局部性),如贪心算法、随机算法
贪心算法
贪心算法求解局部最优解,在局部最优解的基础上再去扩大局部最优解,然而这种方法是具有后效性的,得出的结果不一定是最优的。
随机算法
使用贪心算法,前面子问题的解确定下来后,如果子问题的解导致全局的解不是最优,那么就没有修正的余地了。 而随机算法一般是在局部最优解确定下来后,仍然可以以一定概率进行"变化",以谋求存在一定概率下能打破子问题后效性。
如:遗传算法中,优胜劣汰的规则,会求出局部最优解,但仍然存在一定概率进行"变异",这样可以存在多个局部解,最优解的被选择概率更高,就确保了在子问题最优而全局不是最优的情况下,仍然有一定概率选择其他子问题解,以谋求得到相对更优的全局解。
不同的数据库选用的算法不一样,有的选用贪心,或者动态规划,或者随机退火等等,而postgreSQL的实现较为灵活,当表较少时,选择动态规划,否则选择遗传算法,还可以允许用户自己定义路径算法。
postgreSQL实现
postgreSQL的路径生成算法有三种:
- 动态规划
- 遗传算法
- 用户自定义
路径生成由make_one_rel函数完成,首先为每个基本关系生成不同的访问路径, 再将这些关系作为叶子节点生成JOIN路径。
1 | RelOptInfo *make_one_rel(PlannerInfo *root, List *joinlist) |
生成不同访问路径
遍历所有的关系,为关系生成不同访问路径
1 | static void set_base_rel_pathlists(PlannerInfo *root) |
再看看普通关系如何生成路径的
1 | static void set_plain_rel_pathlist(PlannerInfo *root, RelOptInfo *rel, RangeTblEntry *rte) |
生成基本访问路径后,就开始进行JOIN路径计算了。
1 | static RelOptInfo *make_rel_from_joinlist(PlannerInfo *root, List *joinlist) |
遗传算法
算法
遗传算法:
- 对问题进行编码,确定搜索空间的大小
- 随机初始化群体(主要是给染色体赋初始值,计算每个染色体的适应度的值,并对各个染色体的适应度排序),以及计算好进化次数
- 循环:进行N次进化
- “随机”选出两个染色体,分别是momma和daddy
- 对于momma和daddy使用“杂交”方式,求出其孩子
- 求杂交得到的kid的适应度的值
- 把kid插入群体中(如果kid的适应度比群体中最差的适应度还差,则不插入,否则,替换掉最差的那个且排好序)
- 生成了最优路径
- 根据最优的连接路径生成查询执行计划和花费估算
实现
种群Pool
用来存储染色体,所有染色体在种群中进化出最终的较优染色体。
1 | typedef struct Pool |
基因Gene
最小进化单位,在这里定义成基本关系,Relid
1 | typedef int Gene; |
染色体Chromosome
由基因组成,且由worth来表示此染色体的适应度,适应度差的更高的概率会被淘汰掉。
1 | typedef struct Chromosome |
postgreSQL实现了几种杂交算法
- 基于边重组杂交 (edge recombination crossover)
- 部分匹配杂交 (partially matched crossover)
- 循环杂交 (cycle crossover)
- 位置杂交 (position crossover)
- 顺序杂交 (order crossover)
由于基于边重组杂交是默认的算法,所以我们这里只讨论此算法。
主流程
代码中只保留了基于边重组的杂交算法
1 | RelOptInfo *geqo(PlannerInfo *root, int number_of_rels, List *initial_rels) |
确定种群大小
种群越大,理论上就越能找出最优解,但就会导致计算成本的增加,所以要对种群大小进行取舍。
1 | static int gimme_pool_size(int nr_rel) |
初始化种群
随机初始化种群
1 | void random_init_pool(PlannerInfo *root, Pool *pool) |
生成染色体
改进的Fisher-Yates洗牌算法, 利用了编码有序的特点,将初始化染色体和随机交换结合起来一起进行
1 | // 随机生成连接顺序 |
适应度
geqo_eval函数的主要只有两步
- 通过
gimme_tree函数进行多表连接 - 计算连接结果的适应度值
1 | Cost geqo_eval(PlannerInfo *root, Gene *tour, int num_gene) |
选择染色体
由于种群中的染色体已经按照适应度排好序了,对我们来说适应度越低(代价越低)的染色体越好,因此选择操作基于概率分布的随机。 这样在选择父亲染色体和母亲染色体的时候更倾向于选择适应度低的染色体,同时也有机会选择非局部最优染色体,以达到能够一定随机性。
1 | void geqo_selection(PlannerInfo *root, Chromosome *momma, Chromosome *daddy, Pool *pool, double bias) |
线性随机
1 | static int linear_rand(PlannerInfo *root, int pool_size, double bias) |
先生成一个基于[0, 1]之间的随机值,然后根据概率分布函数求出符合概率密度的随机值。
生成基于某种概率分布的随机数,要先计算其概率密度函数,postgreSQL的概率密度函数为
\[ f(x) = bias - 2(bias -1)x, (0<x<1) \]
bias默认是2,所以 概率密度函数 f(x) = 2-2x,代表概率的变化率。
通过概率密度函数获得概率分布函数
\[ F(x) = \int f(x)dx = bias \times x - (bias - 1) \times x^2, (0<x<1) \]
通过概率分布函数的逆函数法可以获得符合概率分布的随机数
\[ F^{-1}(x) = \frac{bias - \sqrt{bias^2 - 4(bias - 1)y}}{2(bias - 1)} \]
求得概率分布函数如图中红色曲线, 概率分布函数逆函数如图中蓝线,
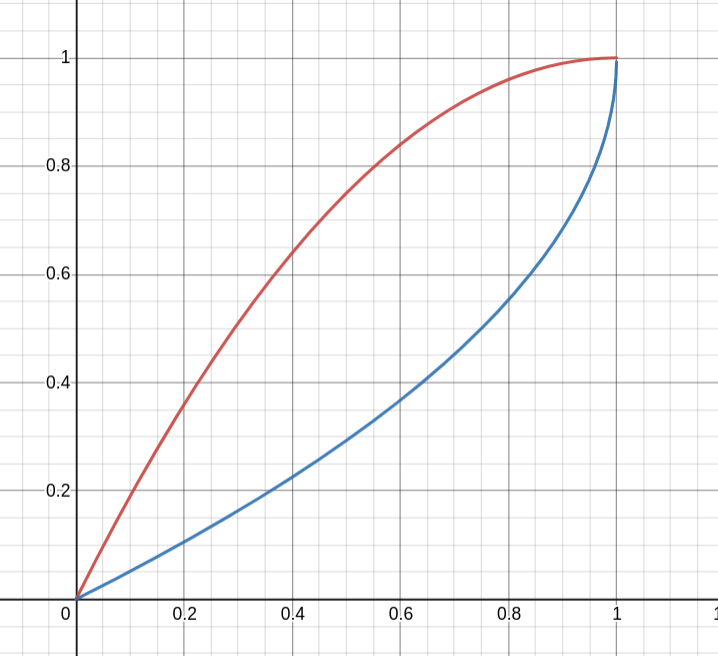
从图中红色曲线可以看出,在X轴上递增,则概率越低(连续型随机变量)。
如:F(x)d(0 ~ 0.2)的概率就比F(x)d(0.4 ~ 0.6)高。
而蓝色曲线是概率分布函数的逆函数,值域(Y轴)为随机变量,在X轴上选定任意的p(0<=p<=1)时,通过逆函数得到的是随机变量的值,也就是获得概率和为p的随机变量的上限。
所以通过逆函数,可以将rand(0, 1) “转换成” 符合概率密度分布的随机值。
测试:将linear_rand代码提取出来,进化10000次,种群选择10,那么10条染色体被选中的概率分别为18.8%,16.9%,15.5%,12.9%,11.3%,9.3%,6.3%,5.1%,2.8%,1.1%,可以看出概率变化是符合概率密度函数 f(x) = 2-2x的。
bias的选择
密度函数中bias越大,则适应度低的染色体被选择概率更高,随着进化次数越多,产生"近亲繁殖"的概率就越高,也就越容易造成贪心算法类似的问题;
bias越小,则"优胜劣汰"的速度越慢,需要的进化次数越多,但是,最终找出最优解的可能性也越高。
杂交算法
默认的杂交算法是:基于边重组的杂交。
算法
如2条染色体
- 染色体1:(A, D, C, B)
- 染色体2:(C, B, D, A)
边关系
- 视染色体为循环队列:染色体1中A与B是有边关系的
- 边关系是双向的:如染色体1中,基因A和D的边关系为(A, D)和(D, A)
我们使用一个边表来存储染色体的基因之间的边关系
- A -> (-D, B, C) : 表示基因A和(D, B, C)有边关系,而(-D)表示有2条这样的边关系,称为共享边
- B -> (A, -C, D)
- C -> (D, -B, A)
- D -> (-A, C, B)
在交叉过程中,会尽量选择共享边,这样可以达到选择较优基因的目的。
边表
边表用来存储染色体中基因的边关系。
1 | typedef struct Edge |
alloc_edge_table分配表边,为总数=基因+1的边。
根据染色体来填充边表
1 | // tour1和tour2为2条染色体 |
通过边表,生成新的染色体
1 | int gimme_tour(PlannerInfo *root, Edge *edge_table, Gene *new_gene, int num_gene) |
从基因的边关系中找出一条“合适的”边关系
- 优先选择共享边关系:共享边是指某条边在父母中都存在,也说明2个基因组成的这条边是较优的,所以要尽量继承下去。
- 从邻居基因的边关系中,找出其边关系最少的邻居
1 | static Gene gimme_gene(PlannerInfo *root, Edge edge, Edge *edge_table) |
这样,我们就通过边重组的方式,产生出较优的染色体。
生成连接路径
根据指定的染色体,生成最佳路径。
1 | RelOptInfo *gimme_tree(PlannerInfo *root, Gene *tour, int num_gene) |
new_clump与clumps中每项进行连接,如果可以连接(且连接顺序符合染色体), 则连接并加入到clumps中,如果不可以,则将new_clump加入到clumps中。
1 | static List *merge_clump(PlannerInfo *root, List *clumps, Clump *new_clump, int num_gene, bool force) |
动态规划
算法
过程
- 第一步 : 初始化第1层关系,为基本关系节点,包含基本关系的数据访问路径
- 第二步 :生成第2层到第n层关系:
- 左右深树连接方式:将第2层到第n-1层的每个关系,与第1层中的每个关系连接,生成新的关系,每一个新关系,均求出最优路径
- 紧密树连接方式:将第k层(2<=k<=n-k)的每个关系,与第other_level层(n-k)中的每个关系连接,生成新的关系放于第n层,且每一个新关系,均求解其最优路径
实现
主流程
1 | RelOptInfo *standard_join_search(PlannerInfo *root, int levels_needed, List *initial_rels) |
计算某层的中间关系
左右深树
PlannerInfo结构上的join_rel_level的用来存储关系,第1层是基本表关系,第2层到第N层是连接关系。
假设A JOIN B JOIN C JOIN D,join_rel_level如下:
join_rel_level[1]:(A),(B),(C),(D)join_rel_level[2]:连接第1层的表(满足JOIN约束),得到(A⋈B),(A⋈C),(A⋈D),(B⋈C),(B⋈D),(C⋈D)- (A⋈B) :路径有(A JOIN B), (B JOIN A) 两种join顺序,
A merge-join B,A hash-join B等不同的join方式。
- (A⋈B) :路径有(A JOIN B), (B JOIN A) 两种join顺序,
join_rel_level[3]:用第1层和第2层的关系连接得到- 左深树: ((A⋈B)⋈C),((A⋈B)⋈D),((A⋈C)⋈D),((B⋈C)⋈D) ,等等
- 右深树:(A⋈(B⋈C)), (A⋈(B⋈D))等等
join_rel_level[4]:用第3层和第1层的关系进行连接- (((A⋈B)⋈C)⋈D), (A⋈(B⋈(C⋈D))) 等等
- 最终生成整个问题的最优路径。
紧密树
紧密树是由两个或多个连接关系之间再进行连接产生的关系。
所以,只有大于3层的关系才能产生紧密树,假如A JOIN B JOIN C JOIN D JOIN E
将第2层之间进行连接:((A⋈B)⋈(C⋈D)), ((A⋈D)⋈(B⋈C)), ((D⋈E)⋈(B⋈C)) 等
将第2层与第3层进行连接:((A⋈B)⋈(C⋈(D⋈E))),
1 | // 计算出level的节点 |
创建关系
make_join_rel用于创建一个新的连接关系并生成此连接关系的路径。
这个新关系的构成的每种方式就是一个路径,并保存于RelOptInfo的pathlist。
1 | RelOptInfo *make_join_rel(PlannerInfo *root, RelOptInfo *rel1, RelOptInfo *rel2) |
1 | RelOptInfo *build_join_rel(PlannerInfo *root, Relids joinrelids, RelOptInfo *outer_rel, RelOptInfo *inner_rel, SpecialJoinInfo *sjinfo, List **restrictlist_ptr) |
生成路径
1 | static void populate_joinrel_with_paths(PlannerInfo *root, RelOptInfo *rel1, |
总结
要枚举出查询树上所有路径,从中找出一个代价最小的路径,是个NP问题,计算成本是非常高昂的。而当查询树的关系(表、子查询等)较少时,可以使用动态规划算法枚举出所有的路径找出最优解,但是当关系较多时,枚举的计算成本是我们无法接收的,这时就需要使用一些折中方案,如贪心算法、遗传算法。遗传算法借鉴自然界“优胜劣汰”的法则对路径进化,从而能找出相对较优的查询路径。
